YADP - Yet Another Distributed Project
Description:
yadp is a distributed application. You can for example, parallelize the processing of large data sets, or, run a task over several hosts. The focus is put both on the parallelization part and on the module which enable the development of the distributed code. The computation task is simplified by parallelizing the program over multiple individual, unreliable, cheap machines. This mechanism is based on an multi-agent system, i.e. each machine can host one or more agents, this system is able to split and distribute the tasks over multiple agents, monitor their execution, simultaneously process others tasks, register new agents, remove disconnected agents, and collect the results. Moreover, by its design, yadp should reduce the amount of time spent and simplify the development of the code having to be distributed and executed over remote hosts. This module provides a common interface with a few concrete class implementations, and is designed to be fully extended in order to fit to any project. The goal of yadp is to hide the complexity of the parallelization, while keeping his power.
Download:
You can download the source code here. You can also watch a screenshot here.
Features:
- The source code is distributed, loaded, and executed by workers. Optionally, an input data set can be distributed, but this is not required. Typically, these data are a set of plain text files or database files. From a design point of view, yadp can virtually accept any input file which can be iterated over (nevertheless, nothing is free, for a specific case it must be necessary to implement your own iterator).
- yadp is fault tolerant (cf. section below), i.e. one or more agent can fail or stop during its execution without disturbing or breakdown the others agents. Simply, a work part will be re-executed later on an active agent.
- An agent must know only one address: the agenda's address. There is not a persistent list of agents hard coded, or something like that, each agent himself declare its activity to the agenda.
- When the work is near to be complete, a back-up task mode is started to speed-up the completion: remaining running tasks are duplicated over free workers and executed in parallel. For a same task, the first worker to return the result win, any other result for the same task is now ignored.
- All the agents, of all kind can simultaneously be hosted and running on the same machine, so that it can be easy to debug or test.
- The agents communicate between them by XML-RPC calls, by using the xmlrpclib module. Each agent implement an XML-RPC server and eventually become client of another server when it needs to request another agent. The resulting benefits are to use a common transport protocol (the http protocol) for exchanging messages, and rely on the XML language for formatting the messages to avoid to write a dedicated parser. Moreover the benefit is huge to use an heavily widespread module instead of writing his own home-made untested (bugged) new (reinvented) module.
- Each agent is multi-threaded, one thread per XML-RPC request (the agent use the XML-RPC server for concurrently handling the external requests), and one more thread for processing the internal routines. For example, an applicant agent post a task to a taskscheduler agent by using an XML-RPC call, and the taskscheduler will dispatch this task to a worker agent.
- Optionally, and only under Linux (yet), each worker agent can check whether if the system is idle (keyboard, and mouse inactivity) before processing a new task.
Architecture and communication between the agents:
The current overall communication architecture between the agents is driven by the following schema:

Moreover, this other figure (here) shows the minimal requirements needed for the system to work. Whereas this last figure (here) presents a more advanced configuration. Note that each node can be located on a different physical host.
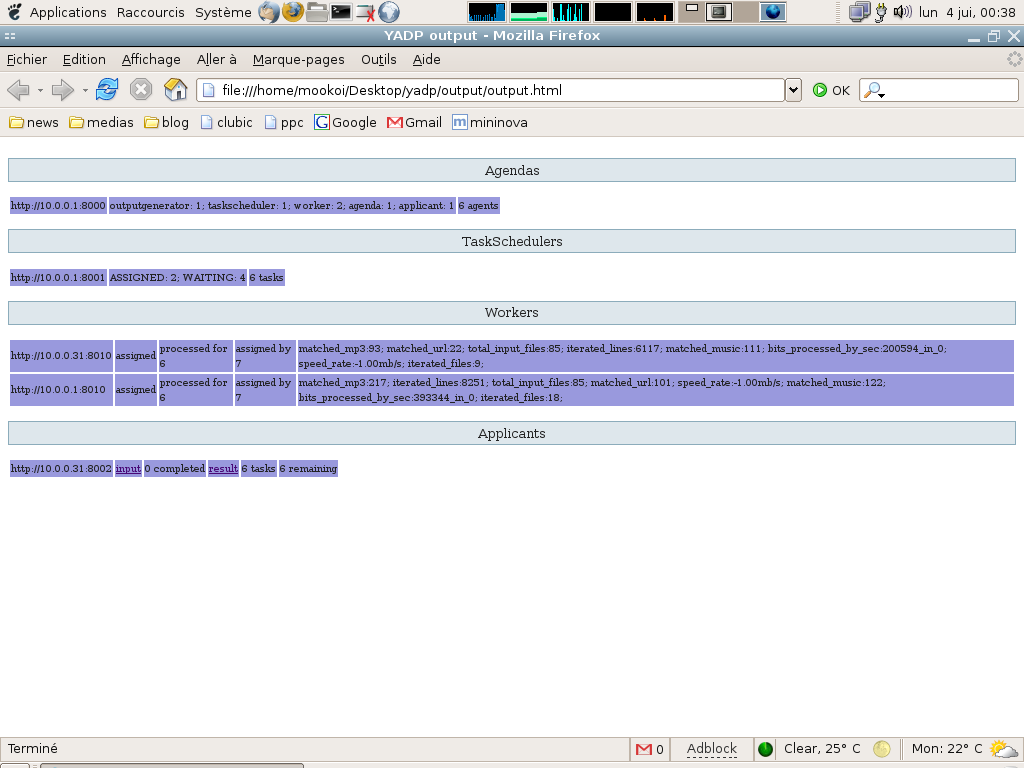
- The agenda agent records and keep in memory all the running agents (whatever their kind, including the agenda himself), and reply to their requests. The requests could ask for an address list of a particular kind of agent, or to remove, or to mutate an agent. Each agent has an unique ident.
- The applicant agent has the responsibility to divide the input data set in chunks (optionally), then to copy the program code having to be executed, make an archive, then finally send the corresponding meta-data to a taskscheduler. Then, this agent only reply to requests which are: send the archives and get the results (if any) on demand. When all the initial tasks are completed, its job is terminated.
- The taskscheduler agent is a task scheduler. applicants requests the taskscheduler and post their tasks. Then the taskscheduler dispatch them over free and operationnal workers.
- The worker agent is the one who run the distributed code and process the input data if any, or make whatever else. This code can compute a part of the result or not. The worker ask for an archive (which contain the program code, and eventually a chunk of data to process) to the applicant agent, then dynamically load and run the received code. Finally he sends an archive (which contain the logs, and eventually some results) back to the applicant.
- The outputgenerator agent dynamically collect informations over all declared agents, then format these informations and produce an human readable html output. You can run as many outputgenerator agents as you want and that without overhead the agents workload. Because, only one outputgenerator agent will ever produce the output at a given time, the number of requests received by each agent will not increase with the addition of a new outputgenerator to the system. Instead, the others agents will request the result directly to him. Moreover, each outputgenerator agent is able to dynamically modify his behavior (mutate), cf. next section.
- The cleaner agent check every minute if every agent is still alive, if one agent is dead, he will be removed from the agenda. Note that this agent is optional, even without him, the dead agents would have been detected, but the cleaner is safer, faster and dedicated for.
Fault tolerance
Since the early developments, the fault tolerance is a top priority. The ability to deal with unreliable hardware, networks, code, and humans is mandatory. So, these characteristics are the foundations in the design of yadp. Either the agent is intentionally stopped or the agent unexpectedly fail, but the handling mechanism is the same. For a worker agent, at worst the assigned task will be re-scheduled on another worker, an applicant, will cancel its tasks, an outputgenerator agent will not anymore produce any output. Nevertheless, if this agent was the producer, another outputgenerator (if one is running) will become the new producer. The breakdown of one will never broke the others outputgenerator, even if it was the producer. For a taskscheduler, the applicant will detect his inactivity and re-post the uncompleted tasks to another taskscheduler. If the agenda stops, which is the central component of the system, all the agents will be unable to communicate anymore, stops their jobs, and waits for a new connection with a new agenda (one with the same address than the former). Once the reconnection established, the remaining tasks will be re-scheduled without additional costs (i.e. tasks re-execution). The cost is function of the time meanwhile the agenda was down.
Technical details and recommendations:
- yadp is written in Python, is only about 2500 lines, and currently run under Linux and Win. As it rely only on the Python library, the portability doesn't seem to be a matter and is probably closely tied to the Python portability.
- yadp use recent features of Python. Thus the version 2.4 or above of Python is required.
- The purpose of yadp is to distribute a program over several machines, thus, as being a worker you must be aware of the risk you take in doing this: the distributed code is not executed in a restricted mode, you can have irreversible damages on a machine hosting a worker agent if the program is bugged or worst if he is malicious. Keep it in mind: if you are hosting a worker you must be able to trust your agenda.
- The outputgenerator dynamically produce an html output, if you want to access it from another machine, you will have to provide an http server, but since that two or more outputgenerator will never overhead your system, you can instantiate as many outputgenerator as you want. Typically a good rule of thumb is: one outputgenerator agent for one host.
- Due to a problem with the httplib module, of the python standard library, yadp is currently unable to distribute data chunks larger than 40Mb (approximatively) from any agent running under WinXP (note: only the applicant agent is supposed to be affected, and only in the case where you choose to distribute a large input task). This problem is limited to the Windows architecture and does not occur under Linux.
sebastien.martini at gmail.com

Last update:01-2006
{kind=link}
{kind=link}
{kind=link}